Trajectory heatmap
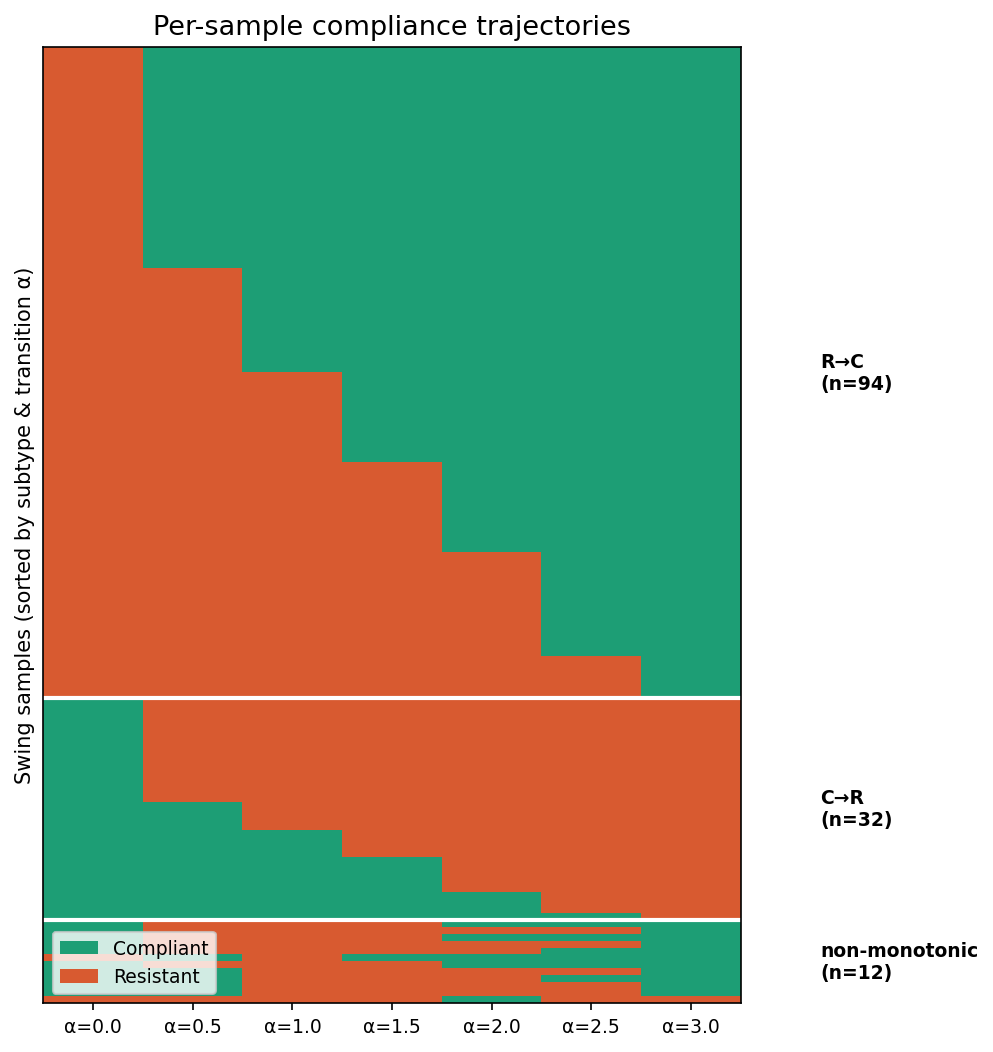
138 samples, 7 alpha values: the full compliance matrix
Each row is one swing sample, each column is an α value (0.0 to 3.0). Orange cells indicate resistant behavior, while green cells indicate compliance with misleading context. The dominant R→C pattern shows up as rows that transition from orange to green as α increases.
Reading the heatmap: if R→C were just noise, you would see a scattered mix of orange and green.
Instead, the transitions form bands: rows stay orange (resistant) at low α then flip green (compliant)
at a specific threshold. That banding pattern is consistent with a genuine decision boundary
being crossed, not random format drift.