Six tests, each asking a different version of the same question
A real hub neuron should survive multiple kinds of scrutiny. We required broad support instead of letting one flattering plot do all the work.
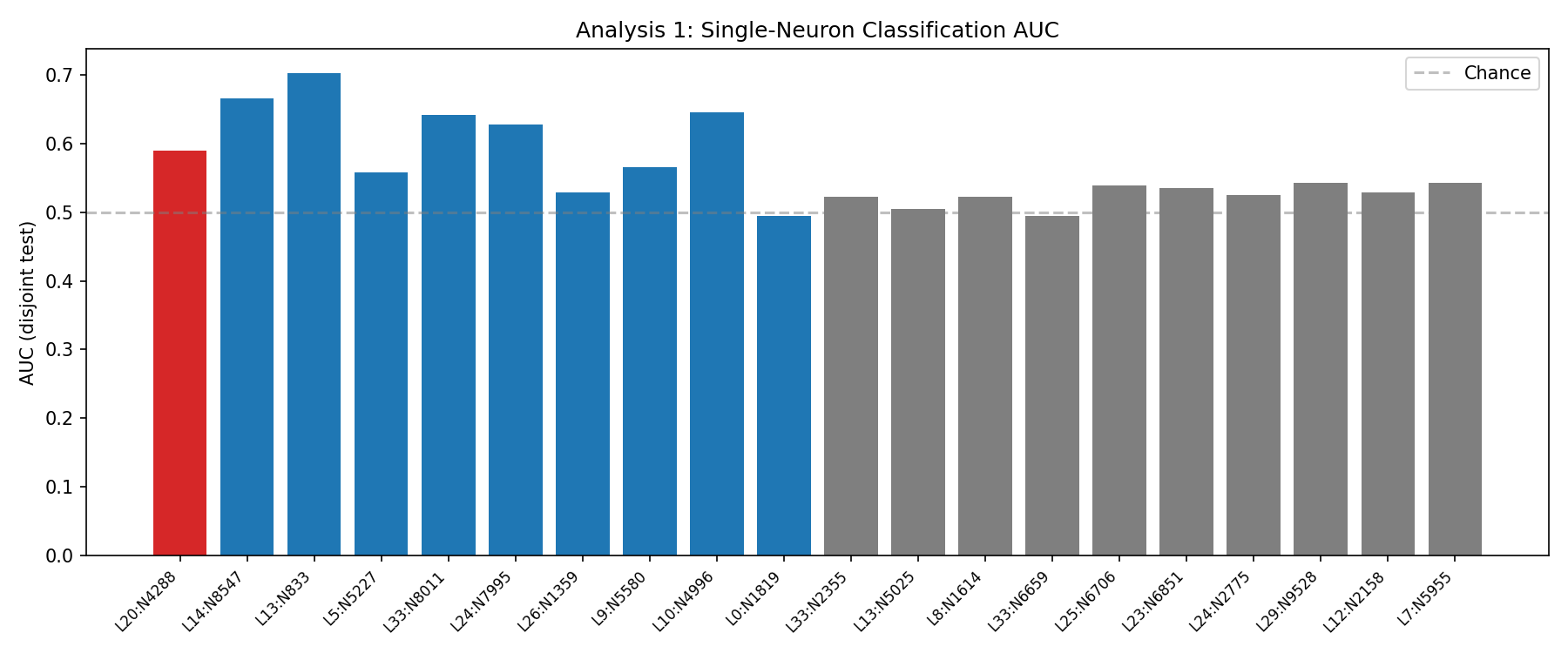
If 4288 were genuinely carrying the detector, it should classify well on its own. Instead its standalone AUC is 0.590, worse than L13:N833 and L14:N8547.
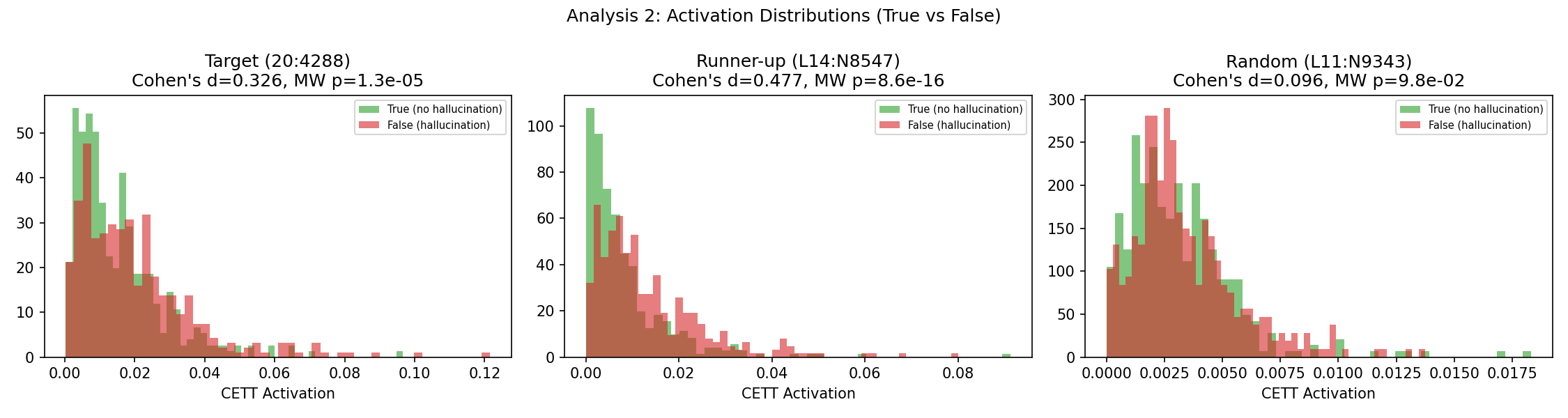
Cohen's d is 0.326, below the 0.5 cutoff we set ahead of time. The activations separate somewhat, but not enough to justify a "special neuron" story.
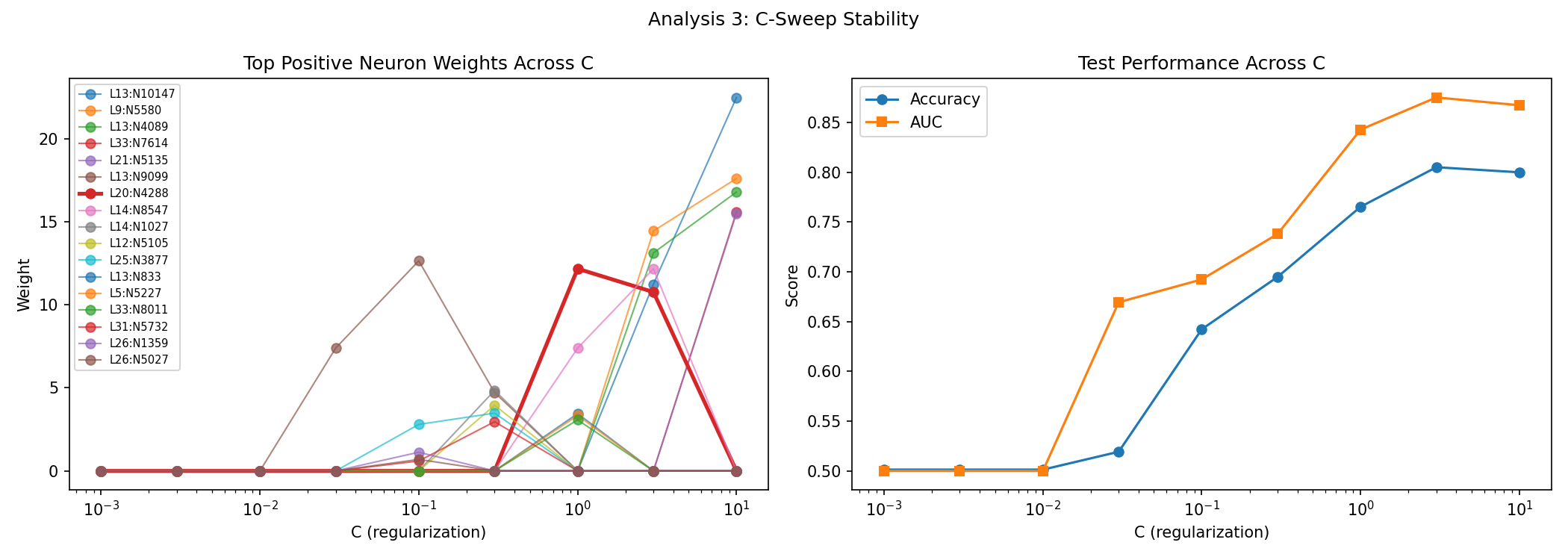
This is the sharpest test. Neuron 4288 is absent at C ≤ 0.3, appears at C = 1.0, then falls to rank 5 at C = 3.0 and rank 11 at C = 10.0. Real mechanism should not be that C-fragile.
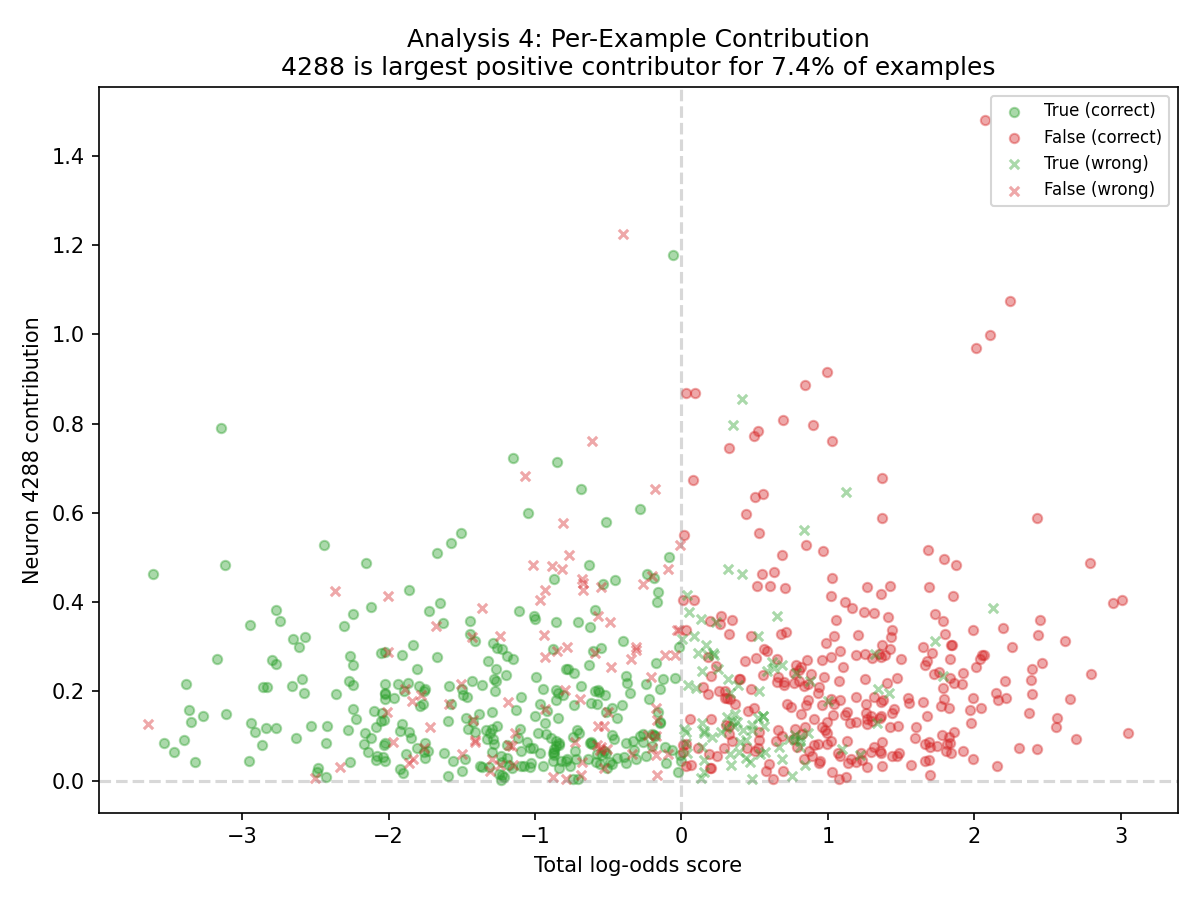
Despite the oversized L1 weight, 4288 is the largest positive contributor on only 7.4% of examples. That is more "frequent committee member" than "single point of control."
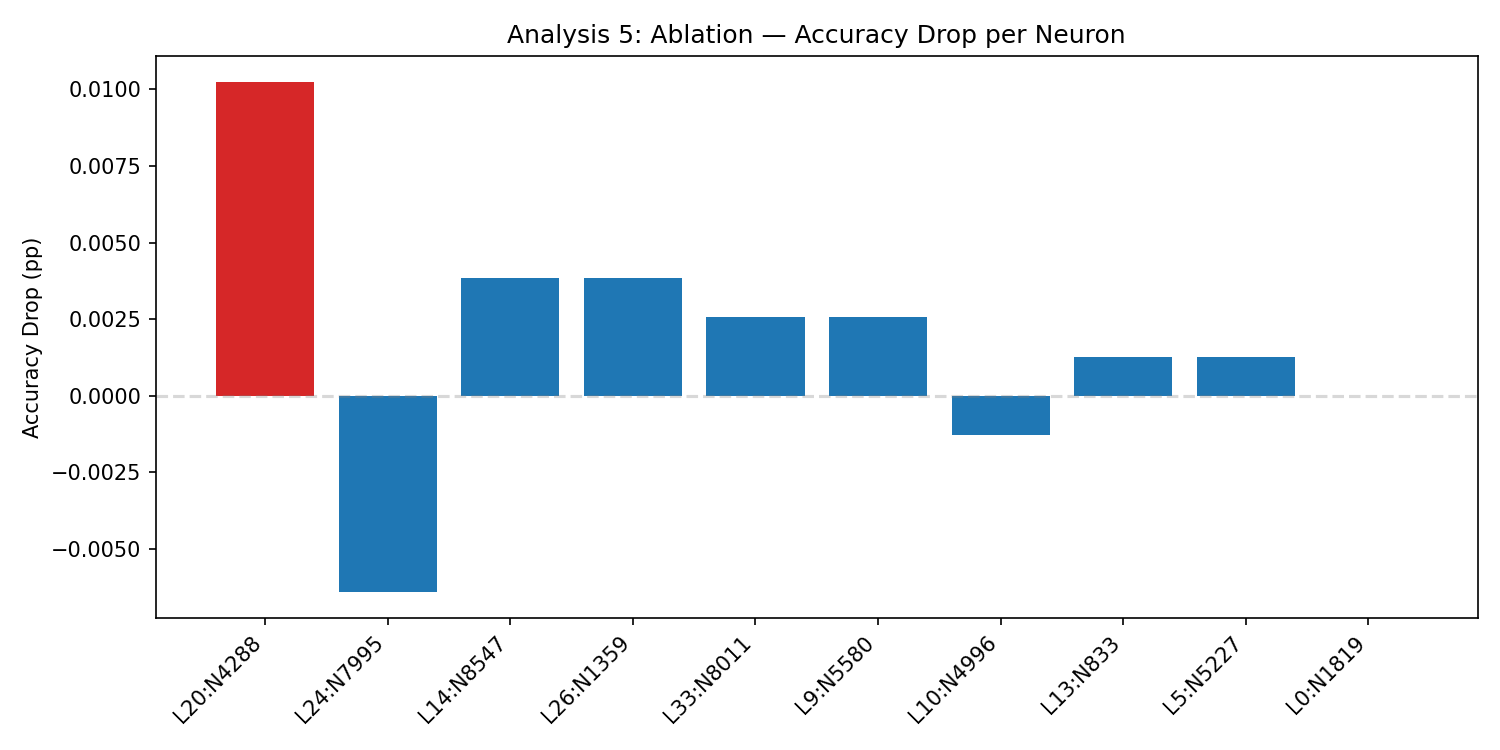
Zeroing the neuron reduces accuracy by 1.03pp, below the 2pp threshold. It matters, but not enough to look like a true bottleneck.
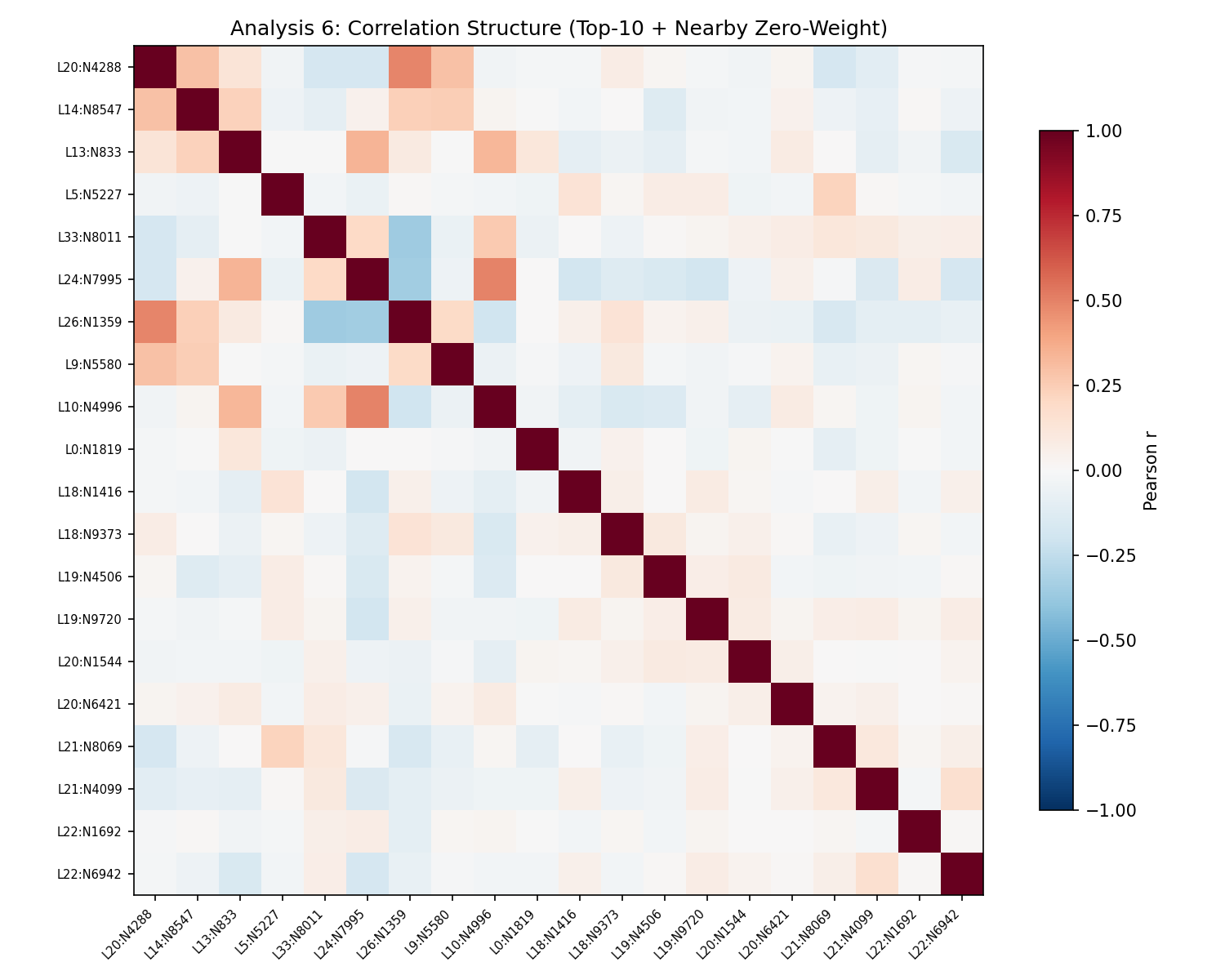
The strongest observed correlation is r = 0.492 with L26:N1359, a zero-weight neuron. That is the exact pattern you expect when L1 picks one representative from a correlated feature group.